TL;DR
KIP-1150 introduces Diskless Kafka topics that write directly to S3 instead of replicating between brokers. It literally reduces costs by 5x+ off of the most optimized Kafka deployment (10x+ otherwise) and brings operational benefits for diskless topics like: no disk management headaches, instant broker scaling, and simplified load balancing. The trade-off is slightly higher latency (a projected end to end p99 latency of ~1-2s vs traditional Kafka’s < 100ms).
The feature has been out in proprietary Kafka implementations for two years now, but the difference now is that it is open-source. This means you can actually pocket the difference in savings.
System Per Day Per Month (30 days) Per Year (365 days) Latency (p99 e2e) Supports Classic + Diskless Freight (Confluent) $5,887.92 $179,637.60 $2,149,091.00 < 2s ❌ Classic Kafka (Tiered) $2,894.66 $88,004.00 $1,056,048.00 < 100ms ✅ Diskless Kafka (KIP-1150) $522.33 $15,666.9 $190,650.45 < 2s ✅
⚠️ This blog is a supplement to the Diskless Topics newsletter edition - https://blog.2minutestreaming.com/p/diskless-kafka-topics-kip-1150
To keep it consistent with the Kafka example used later in the newsletter, we assume:
- Producers: 500 MB/s in
- Consumers: 1500 MB/s out
- 7 days retention
Freight Comparison
Confluent Freight is a direct comparison to diskless topics, with the following benefits and drawbacks:
- ✅ it is completely self-hosted. You spend no effort in setting it up or managing it.
- ❌ it only supports slow topics. You can’t have fast and slow topics in the same cluster.
We will compare infra costs.
Why this comparison?
It’s not a fair comparison. Freight is a SaaS. Diskless would be self-hosted, which means you need to manage everything and use engineering resources to set it up and maintain it.
All vendors like to boast TCO savings while taking into account the reduction of number of engineers required to maintain the cluster. I am personally a bit skeptical of these claims, because I think most of the Kafka engineers’ work goes into setting up security, managing company-wide conventions, documentation, supporting app developers with best practices/etc. - and a managed service doesn’t take all that away from you.
As for why Freight - well, it’s just the most egregious example of these diskless solutions. Every vendor is expensive and I don’t mean to make Confluent stand out here. I’ve compared WarpStream before too, which is one of the cheapest vendors. (now owned by Confluent too though)
As I’ve said before - every vendor is talking their book. I’m trying to talk your book.
Freight Cost ($2M+)
- Throughput is priced at a fixed cost per GiB, depending on volume: https://www.confluent.io/confluent-cloud/pricing/?pillar=stream&modal=volume_pricing_section
- We push 2000 MB/s, which after one month results in 5108.64 TiB - so we get the max discount of $0.03/GB
- 5231247.36 GiB at $0.03 is $156,937 a month; $1,883,249 a year. In networking fees. The whole goal of this design was to save on networking?
- Storage is $0.08/GiB a month; At 500 MiB/s with 7 day retention, we store 288.39 TiB (295311.36 GiB). A big gotcha is that Confluent charge you post-replication,so the price is $0.024/GiB, so the storage price is $7087 a month; $85,050 a year.
- 9 CKUs will cover this workload, at $2.25/hr - $15,066 a month; $180,792 a year.
Total: $2,149,091 a year. That’s $2.15M a year for the cheap option.
Classic Kafka Cost ($1M+)
I’ll spare you the deets and just run my calculator:
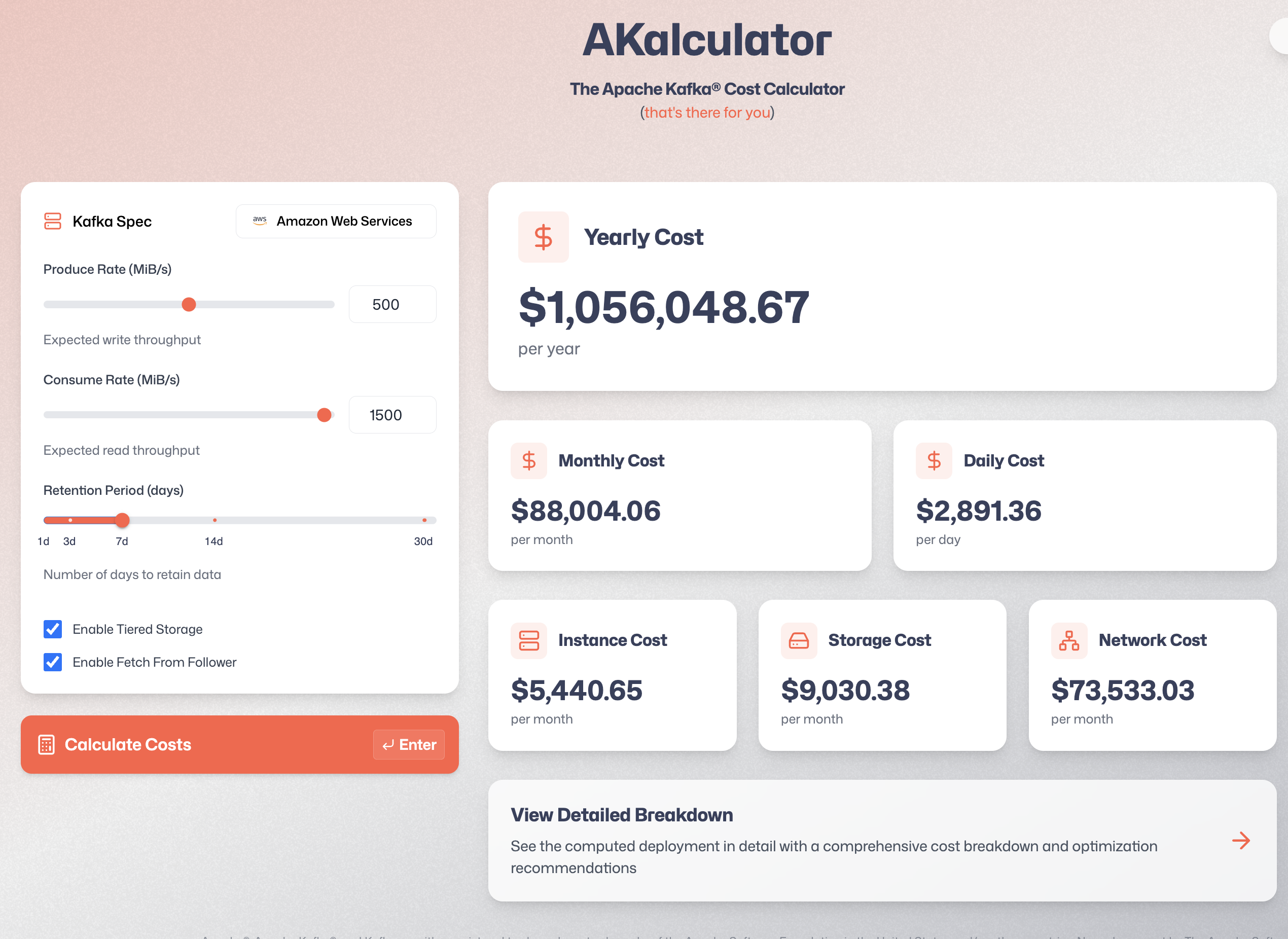
This is using Tiered Storage, Fetch From Follower and a cluster with gp3 SSDs.
Total: $1,056,048 a year. That’s $1.05M a year for self-hosting regular Kafka.
Diskless Kafka Cost ($190k)
Since the proposal isn’t finalized completely and things are subject to change, treat this a bit as napkin math. In any case, the cost shouldn’t change by more than 5-10%, because the major cost drivers (800k in networking) are removed.
- assume we have a 6-broker Kafka cluster
- assume we have 500 MiB/s of compressed producer traffic. Each broker therefore receives 83.3 MiB/s.
- I emphasize compressed because many vendors advertise uncompressed (big gotcha).
- assume our KIP-1150 batch size is configured at 16 MiB and our batch interval at 250ms. Because each broker issues a PUT every 16 MiB, its effective batch interval is 192.07ms.
- assume 1500 MiB/s of consumer traffic across 6 brokers (3x fanout), all reading from the tail of the log.
KIP-1150 Costs
Request Counts
- S3 write: each broker does 5.2 PUTs a second, the whole cluster does 31.23 PUT/s
- round up to 32 PUT/s
- coordinator write cost: each PUT results in one call to the BatchCoordinator. The whole cluster issues 32 Batch Coordinator requests a second. This is implemented with a classic Kafka topic, so our only real cost is the storage + replication. Let’s handwave, be extremely charitable and assume a 10 MiB/s metadata traffic for the 500 MiB/s of data traffic.
- 10 MiB/s BatchCoordinator produce
- merging: while still unspecified how and when, the many small objects created with the initial PUTs get merged into larger ones. We can assume that this requires at a minimum reading the data once (one S3 GET per file), writing it out in larger multi-GiB objects (e.g. with 1 multi-part PUT per 25 MiB) and updating the BatchCoordinator (let’s just handwave this to an additional 1 MiB/s of traffic). How big our new merged files doesn’t matter with relation to the cost calculation, because we will always upload them via multiple smaller multi-part PUT requests.
- 32 GET/s
- 1 MiB/s BatchCoordinator produce
- 20 multi-part PUT/s (500 MiBs / 25 MiB multi-part size)
- reads: caching plays a very important role here for e2e latency. We should assume that any write going into a broker is cached for that availability zone. Because 1/3rds of producer traffic is always in the same zone, we can roughly assume that 1/3rds of the read traffic is always cached. At 1500 MiB/s reads, roughly 1000 MiB/s of read traffic will have to be fetched from S3. It would be more efficient if the reads could be served from the larger merged files, but let’s be conservative and assume we are going to be reading from the small files. This results in roughly 62.5 GETs/s for the cluster (1000 MiB / 16 MiB file size). In practice, it’s probably a bit less due to caching and the fact that two requests may require portions of the same cached-once 16 MiB file. In any case - you will see it doesn’t matter because GETs are dirt cheap (10x cheaper than PUTs).
- 62.5 GET/s
- coordinator reads: we are venturing further out into speculation territory - it’s really unclear to me how many reads brokers would need from the BatchCoordinator’s backing store. Let’s stay super conservative and assume it is 3x.
- 30 MiB/s BatchCoordinator reads
Daily Values
There are 86400 seconds in a day.
- data: the cluster receives 42189 GiB of fresh data every day
- S3 writes: 4,492,800 PUTs a day
- 52 PUT/s (32 PUT/s for writes and 20 PUT/s for merging)
- S3 reads: 8,164,800 GETs a day
- 94.5 GET/s
- coordinator writes: 843.75 GiB Batch Coordinator produce a day
- coordinator reads: 2531.25 GiB Batch Coordinator consume a day
Cloud Prices
Our costs are:
- S3 GET: $0.0004 per 1000 requests
- S3 PUT: $0.005 per 1000 requests
- S3 DELETEs: free
- S3 Storage: $0.023-$0.021 per GiB-month
- BatchCoordinator replication: $0.02/GiB for cross-zone traffic
- BatchCoordinator storage: $0.08/GiB for EBS SSDs (note we have to pay for the 3x replicated data, as well as pay for provisioned free space)
- BatchCoordinator Produce: each GiB results in ~2.66 GiB in cross-zone traffic (2x for replication, 0.66x for the produce traffic as 2/3rds crosses zone) and 6 GiB of storage (as it’s durably replicated 3x and we keep 50% free space)
- BatchCoordinator Consume: each GiB results in ~0.66 GiB in cross-zone traffic (0.66x for the consume traffic as 2/3rds crosses zone)
- m6g.4xlarge: $0.616/hr on demand (3yr reserved is 3x less, but we stay conservative)
- Kafka Controllers r4.xlarge: $0.266/hr on demand
Daily Cost Calculation
A KIP-1150 topic receiving 500 MiB/s of trafic and serving 1500 MiB/s of reads, with our very extremely conservative batch coordinator estimates, should roughly cost $503.18 a day.
- S3 writes: $22.464/day (4,492,800 PUTs a day @
$0.005/1000)- includes merging and writes
- S3 reads: $3.26/day (8,164,800 GETs a day @
$0.0004/1000) - coordinator writes: $136.35/day
- cross-zone networking: $44.9/day (843.75 GiB * 2.66x amplification @
$0.02/GiB) - storage: $91.45/day ($2835/month) (843.75 GiB produce * 6x storage amplification @
$0.08/GiB-month, 7 day retention)
- cross-zone networking: $44.9/day (843.75 GiB * 2.66x amplification @
- coordinator reads: $33.41/day (0.66x * 2531.25 GiB cross-zone traffic @
$0.02/GiB) - instances: $107.85/day (6 m6g.4xlarge @
0.616/hrand 3 r4.xlarge @0.266/hr) - S3 data storage: $219/day ($6792/month) (288.39 TiB of data stored in S3, 7 day retention)
$522.33/day.
There are 365 days in the year… so:
Diskless Kafka costs $190,650.45 a year.
Conclusion
By being open-source, Diskless Topics can save you 11.2x (‼️) the cost of alternative fully managed implementations. This comes on top of other benefits, such as eliminating vendor lock-in.
| System | Per Day | Per Month (30 days) | Per Year (365 days) | Latency (p99 e2e) | Supports Classic + Diskless |
|---|---|---|---|---|---|
| Freight (Confluent) | $5,887.92 | $179,637.60 | $2,149,091.00 | < 2s | ❌ |
| Classic Kafka (Tiered) | $2,894.66 | $88,004.00 | $1,056,048.00 | < 100ms | ✅ |
| Diskless Kafka (KIP-1150) | $522.33 | $15,666.9 | $190,650.45 | < 2s | ✅ |
Side-note: Freight being marketed as up to 90% cheaper than self-hosted Kafka, yet ending up 2x more expensive is more proof why you should not trust any vendor’s cost saving claims. (I’m guilty of falling for this too before I knew anything about cloud costs)