In case you haven’t been following, the event streaming Kafka space has been in fierce competition recently1.
What used to be dominated by unicorn-turned-public-company Confluent now consists of 20+ vendors (of which IBM controls 5 now after it bought Confluent)2.
What’s been peculiarly interesting in this dogfight has been companies’ slow pivot away from their proprietary-solutions and heavier lean into open-source and the Kafka protocol.
The latest example is StreamNative. Traditionally the Apache Pulsar company3, they just released a blog post called “We are a Kafka Company, Too” where they detailed how they’ve chosen to fork a new version of Kafka (4.2) and add a new, opt-in diskless write/read path that utilizes their to-be-open-sourced Ursa storage engine. This fork also supports the classic Kafka write/read paths and API since it is literally Kafka.
What does Ursa bring to Kafka
At a high-level, Ursa is a “diskless”4 storage engine.
The best technical read on the matter is this 2025 VLDB paper (with which they won the best industry paper award).
The high-level benefits I see are:
- diskless topics and all their goodies:
- 10x lower infra costs - no cross-AZ network traffic (which can be 90% of the cost), no triple EBS storage costs and less compute; (as the replication work is now outsourced to S3)
- instant scale-ups/scale-downs - because Diskless Topics don’t store state on the local disk and are leaderless (any broker can serve writes/reads for them), extra nodes can be spun up/down as easy as Nginx5;
- no hot spots or need for heavy rebalances - without stateful leaders, it’s easier to spread the load and trivial to rebalance once needed (unlike Kafka’s heavy rebalances that can take hours6)
- simpler ops - no disk space to manage, no rebalances to manage, no more hour-long unclean shutdown times (brokers shut down and start up quickly), and the whole replication dance (under-replicated partitions, ISRs, etc.) is gone and outsourced to S3
- native open-table format support - the topics are directly stored in Iceberg/Delta and registered in the appropriate catalog, through the core, first-class write path of the system.
- auto-DLQ (dead letter queue) for bad schemas7 - doesn’t get your whole lakehouse pipeline stuck on a single bad message
- single copy of the data - because the Iceberg/Delta integration is zero-copy, you don’t pay double for the conventional approach of storing data both in Kafka and in the lakehouse.
- single governance - similarly, you’re only securing, auditing, managing one copy in one system (instead of two)
- seamless upgrades - since it’s just a Kafka fork with minimal changes, deployment should be as easy as a regular Kafka version upgrade (e.g changing your docker image tag). The Ursa fork should pick up your Kafka’s existing state from its regular state stores (the KRaft log, the local log segments, the Tiered Storage bucket).
- rolling back to a regular Kafka version should also work seamlessly. But you would lose your Ursa-backed topics.
- adaptable topics at the flip of a switch - the Ursa fork supports Diskless topics and regular topics in the same cluster, switchable with a simple config8.
- less operational sprawl - many other systems force you to host at least two Kafka clusters for both types of workloads. (high-latency diskless, and low-latency classic) This results in two completely separate clusters to configure, secure, upgrade, observe, maintain, keep a mental map for, etc
In other words, Ursa gives you a Kafka with the option of a modern, leaderless, fully diskless {Iceberg, Delta Lake}-native topic option.
A note on Competition
While it isn’t necessarily a “hot” startup, these guys have some serious engineering firepower behind them. They’ve:
- architected Apache Pulsar9
- were the first in streaming to separate compute from storage
- created a ZooKeeper/etcd replacement specialized for high scalability (Oxia10, Apache-licensed and in the CNCF incubator).
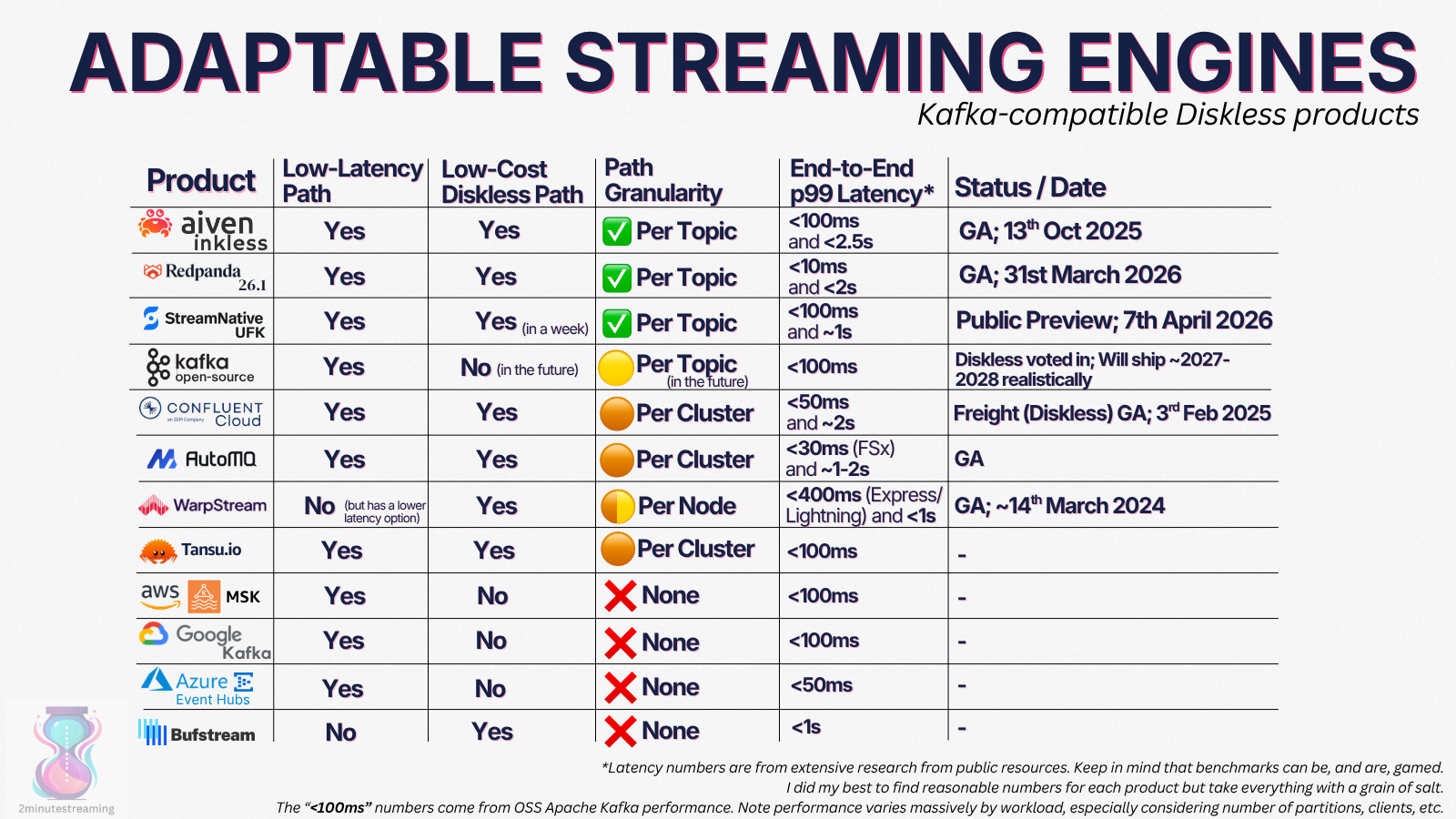
The Kafka space is not short of worthy competitors though. I’ll save you the full 20+ product comparison and concisely zoom in on two areas where Ursa stands out to me:
- Open Table Format integration
- Adaptable Topics
Whether you need these options enough to value their benefits, and whether you can tolerate the trade-offs that come with them, is a separate question that I won’t get into.
1) Lakehouse Native Competitors
Everybody in the Kafka space has some form of an open-table-format sink service today. The ones that have integrated it natively into their product are much fewer - just:
- Bufstream
- Ursa
First-class integration in the critical path matters because it significantly changes the SLA guarantees. It’s not a connector bolted on the side that may or may not be polished and monitored.
2) Adaptable Topics
Similarly, a majority in the Kafka space have some form of low-cost, high-latency topic option. One crucial place where they differ is the ability to host different types of topics inside the same cluster.
The three adaptable solutions are:
- Aiven Inkless
- StreamNative Ursa for Kafka
- Redpanda 26.1
 (open in a separate tab to zoom in)
(open in a separate tab to zoom in)
Note that it’s been decided that this type of topic flexibility is coming into OSS Apache Kafka too via KIP-1150, but realistically-speaking it’s 1-2 years away. (it’s actually driven by Aiven)
What Does This Mean for Kafka
Right this very moment, nothing too actionable. StreamNative has yet to open-source this engine11, so you can’t plug-and-play with it yet.
To me, this announcement solidifies the peculiar trajectory that the Apache Kafka project has been on - one where the open-source repo is steadily losing its gravitational pull.
The Kafka protocol has outlived it all. It is beyond Kafka. It is beyond any single engine.
The Network Effect (and its Future)
Frequently called the “TCP/IP of your data layer”, “the lingua franca for streaming workloads”, “the open standard for data streaming”, “the de facto standard”, Kafka definitively won the protocol war in an endless cycle of network effects and game theory12.
That same protocol is for-all-intents-and-purposes controlled by IBM. Among Confluent, Red Hat and IBM - they control a good chunk of over 80% of open source Apache Kafka activity. (including the PMC (Project Management Committee))
What happens next is the big question:
- Many people have said that the Kafka API is too complex for a majority of use cases.13.
- The protocol itself has not materially changed at all since inception.
- Does it keep dominating without moving?
- Do we see efforts in simplifying it?
- Or, do we eventually see people opting for minimalistic solutions?
Until that’s decided, us in the Kafka camp get to enjoy the benefits of increased vendor competition. More choices are good for everyone.
Footnotes
-
The last front in the war was “Diskless Kafka” - a clever type of architecture that leverages object-storage as its storage engine exclusively. This comes at the trade-off of higher latency (because you need to batch writes, and because S3 is slow) but at massive operational simplicity, code simplicity and a 10x lower cloud bill (S3 is priced dirt-cheap relative to the rest of the cloud).
 (open in a separate tab to zoom in) ↩
(open in a separate tab to zoom in) ↩ -
Aiven Kafka, Alibaba AsparaMQ for Kafka, AutoMQ, Amazon MSK, Bufstream, Azure Event Hubs, Canonical Kafka (yes, even the Ubuntu guys), Confluent, Cloudera, Datastax Astra Streaming (it’s Pulsar, but with a Kafka API), DigitalOcean, Google Cloud Kafka, Heroku, Huawei DMS for Kafka, IBM Event Streams, Instaclustr Kafka, Oracle, OVHCloud, Redpanda, RedHat, Tencent Cloud EMR-Kafka, Tencent CKafka, StreamNative, WarpStream; Out of the above, 1) WarpStream, 2) Confluent, 3) Datastax, 4) RedHat and 5) IBM Event Streams are all owned by IBM. ↩
-
It’s founded by 2/3 of the Apache Pulsar creators, and employs the majority of Pulsar committers/experts in the world. Here’s a good story of how the company came to be. ↩
-
Excuse my buzzword usage, but it’s the most concise way to explain this. Diskless in the Kafka world we’ve taken to mean storing data directly in object storage (e.g S3) instead of local disks, thereby outsourcing high-availability, durability, scalability and elasticity to the object storage system. Here is how Apache Kafka describes it and here is another explanation I found good. PS: Yes, I know disks are still used in the classic path, I know that S3 uses disks underneath too, and I know that for some people the word can imply in-memory when in fact it’s not. ↩
-
Assuming those nodes are exclusively used for Ursa diskless topics. Otherwise, classic Kafka topics on the nodes would still come with their drawbacks. ↩
-
Trust me, I was the technical lead for the Kafka load balancing team at Confluent. ↩
-
In Kafka, schema validation is done in the client. A {malformed,buggy,malicious} producer is technically free to send a non-conforming-to-the-schema message to the topic. This breaks all downstream schema-expecting consumers without special handling. I’ve been vocal on this before. The same applies to any pipeline that would store the data in an Iceberg table.
 ↩
↩ -
Apparently, just a simple
ursa.storage.enabled=true. (src) ↩ -
Pulsar was frequently hailed to be technically better than Kafka, mainly due to its superior architecture that gave it more topics (up to a million), multi-tenancy and better operability. Here is a good in-depth piece on the matter. As someone heavily-biased toward Kafka, I actually don’t disagree. It’s a great example of how we don’t evaluate a system based solely on its technical merits or number of features. The ecosystem’s network effect and commercial vendor maturity matter a ton. While the Pulsar project started internally at Yahoo around the same time Kafka started at LinkedIn… it was only open-sourced in late 2016 and graduated as a top-level Apache project in 2018 - a full 6 years after Kafka. ↩
-
I find this system very interesting and mean to dig down deeper into it. A tl;dr is that it’s sharded, which makes the fundamental trade-off of not allowing easy cross-key atomic operations, but then allows for much higher write/read rates and larger state. This fits the Kafka partition model very nicely. Here is a good blog resource and a good video presentation. ↩
-
They most recently (April 10) committed to open-sourcing it in 9 months time; In the meanwhile, the formally-verified leaderless log protocol was open-sourced. It can make a fun weekend project of claude-coding an implementation. ↩
-
Once a large, sticky base of clients that expect the Kafka wire format started to form, the economics for every vendor creating a new streaming system flipped. They could either invent a new API and spend a decade convincing people to rewrite their applications, or they could implement the Kafka protocol and sell much more frictionlessly (“drop-in replacement”). And that’s what happened - the 20+ products I showed earlier are all, on paper, competition for the Apache Kafka broker. In practice, they’re all a multi-year’s worth of effort vote FOR the Kafka protocol. ↩
-
Kafka was designed to be unopinionated and very flexible. This is appreciated by expert users, but for novices its 300+ config options (and the permutations therein) can be overwhelming. There are examples in the wild like OpenAI, who went out of their way to simplify the protocol in an effort to get internal adoption up. (and it worked very well!) ↩