The Log is the data structure that Kafka is based on. It’s very simple.
It’s an ordered structure of bytes that only supports appends — you can’t edit or delete records in place.
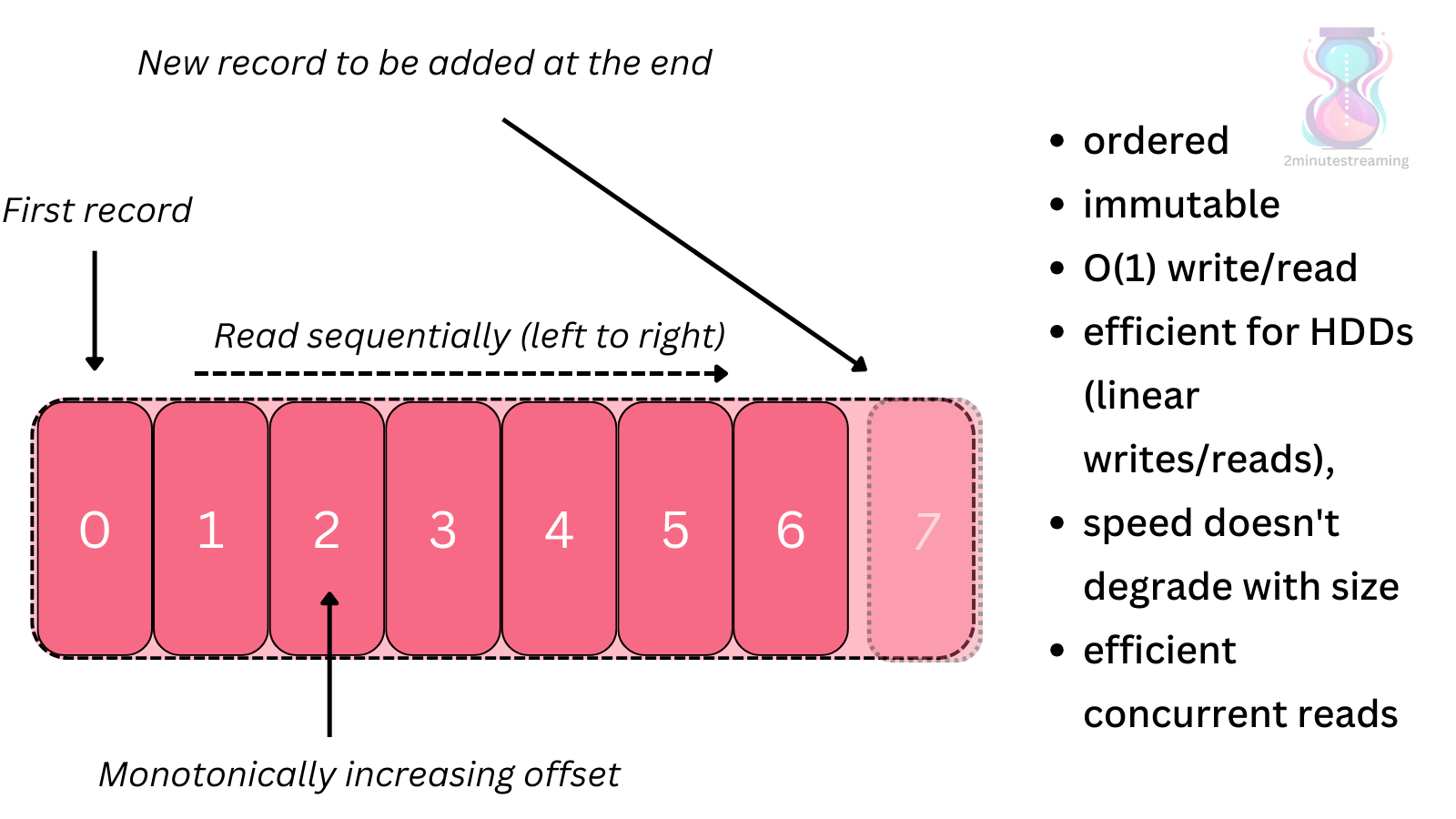
💡 In Kafka, the order is denoted by the monotonically increasing offset. The log starts at 0, so the first record is at offset 0. Second at 1, and etc.
There are a lot of benefits to it:
-
ordering: records are ordered sequentially as they’re ingested, so you know what comes after which.
-
fast: writes and reads from the end (tail) of the log are O(1)
-
HDD-friendly: it’s incredibly efficient for hard drives because of its sequential read/write patterns. This aligns with how HDDs perform best — large, linear IO operations through its mechanical actuator arm and spinning platter design. It benefits from OS-level and hardware-level IO batching.
-
big data friendly: its performance doesn’t degrade with size. A 20TB log performs roughly the same as a 1GB log.
-
read parallelism friendly: because it’s append-only, there is no need for locking when multiple readers are accessing it.
-
simple: it’s easy to understand, easy to optimize for and easy to implement. That’s worth a lot.
It is a core reason for why Kafka is so fast. 🔥🏎️
💡 {Log, Write-Ahead Log (WAL), Commit Log, Transaction Log} are all the same thing underneath - a log. The only difference is what payload it carries.
Application Logs also use the same underlying structure - an append-only sequence of string messages coming from your app.